Tools frequently used by Oracle DBA
Everything is Easy when you are Crazy and nothing is Easy when you are Lazy.
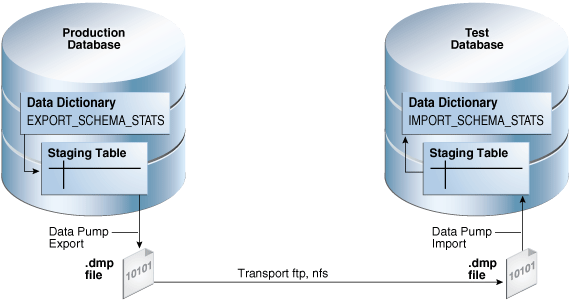
Some hands on with Oracle export/import
So today I will share some tips/tricks with reagrding to Oracle export/import(expdp/impdp). We will not be discussing the lagacy exp/imp here. We will go through some tips and tricks helpful in different senarios during import or export.
Situation 1: I want to export a user schema lets say BANKUSR from production to test for devlopment for further testing purpose.
Challanges:
- The test env already have BANKUSR schema
- The physical structure of test db instance is different from prod db instance
Solution: Whenever we are in above mentioned situation, we can trick it by using appropriate parameter like REMAN_SCHEMA, REMAP_TABLESPACE.
Also there are some few remap parameters which i would like to discuss here:
remap_data: It can we used for permanent data masking during logical restore, which will take the sources original value of the designated column and returns a remapped value that will replace the original value in the dump file but you have to develop a masking function and specify explictly.
The basic syntax is: REMAP_DATA=[schema.]tablename.column_name:[schema.]pkg.function
If you want more please refer to like : Oracle Logical Backup.
remap_datafile: This parameter is greatly helpful when you are doing a whole database migration and are not interested to directory structure same as previous you can do it by providing appropirate parameters.
The below listed parameters more general and widely used:
remap_schema: Use when source and destination schema name are/want different
remap_table: Use when source and destination table name are/want be different
remap_tablespace : Use when source and destination tablespace are/want or are different
Situation 2: You are given a dump file from production and told to restore.
Challanges:
- You are not known whether its done by expdp or lagacy emp
- You are not given physical/logical structure details
- You are not given the schema user details
- You are not known the database characterset
Solution: So few challanges right, what should one go for next. As enumerated above we will also make our action plan according to them.
1) Identify whether it was done with expdp/exp So our first step would be to identify the tool that was used to take logical backup. We can do it by using unix command strings & head.
[oracle@oradr ~]$ strings appmeta.dmp | head -5
"SYS"."SYS_EXPORT_SCHEMA_01"
x86_64/Linux 2.4.xx
orcl
US7ASCII
11.02.00.00.00
So if you encounter similar like EXPORT_SCHEMA, then we can conclude it was taken with expdp otherwise was lagacy exp.
2) Identify the database characterset With above command you can also get the characterset of the source database as in above case is US7ASCII.
3) Identifying the schema name and logical structures The step is simple, we can do it by generating ddl first. We do not need to know schema name, logical structure of source database where the dump file was exported from in prior.
[oracle@oradr ~]$ impdp dumpfile=hr.dmp sqlfile=hr.sql directory=dump_dir
Import: Release 11.2.0.4.0 - Production on Mon Jun 18 03:33:21 2018
Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved.
Username: /as sysdba
Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, Oracle Label Security, OLAP, Data Mining,
Oracle Database Vault and Real Application Testing options
Master table "SYS"."SYS_SQL_FILE_FULL_01" successfully loaded/unloaded
Starting "SYS"."SYS_SQL_FILE_FULL_01": /******** AS SYSDBA dumpfile=hr.dmp sqlfile=hr.sql directory=dump_dir
Processing object type SCHEMA_EXPORT/USER
Processing object type SCHEMA_EXPORT/SYSTEM_GRANT
Processing object type SCHEMA_EXPORT/ROLE_GRANT
Processing object type SCHEMA_EXPORT/DEFAULT_ROLE
Processing object type SCHEMA_EXPORT/PRE_SCHEMA/PROCACT_SCHEMA
Processing object type SCHEMA_EXPORT/SEQUENCE/SEQUENCE
Processing object type SCHEMA_EXPORT/TABLE/TABLE
Processing object type SCHEMA_EXPORT/TABLE/GRANT/OWNER_GRANT/OBJECT_GRANT
Processing object type SCHEMA_EXPORT/TABLE/COMMENT
Processing object type SCHEMA_EXPORT/PROCEDURE/PROCEDURE
Processing object type SCHEMA_EXPORT/PROCEDURE/ALTER_PROCEDURE
Processing object type SCHEMA_EXPORT/TABLE/INDEX/INDEX
Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/CONSTRAINT
Processing object type SCHEMA_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS
Processing object type SCHEMA_EXPORT/VIEW/VIEW
Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/REF_CONSTRAINT
Processing object type SCHEMA_EXPORT/TABLE/TRIGGER
Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS
Job "SYS"."SYS_SQL_FILE_FULL_01" successfully completed at Mon Jun 18 03:33:29 2018 elapsed 0 00:00:03
[oracle@oradr ~]$
Afer generating sql only, we will use some unix command like cat, grep and sort to find the schema name.
[oracle@oradr ~]$ cat hr.sql | grep 'CREATE USER'
CREATE USER "HR" IDENTIFIED BY VALUES 'S:891636E9E2A56E429380E30CBCF20B678EA0CCE21F41CC3C50F4693E9C8F;4C6D73C3E8B0F0DA'
[oracle@oradr ~]$
After knowing the schema name then we will find what tablespace the schema uses.
[oracle@oradr ~]$ cat hr.sql | grep TABLESPACE| sort -u
DEFAULT TABLESPACE "USERS"
GRANT UNLIMITED TABLESPACE TO "HR";
TABLESPACE "EXAMPLE"
TABLESPACE "EXAMPLE" ;
TABLESPACE "EXAMPLE" PARALLEL 1 ;
TEMPORARY TABLESPACE "TEMP";
[oracle@oradr ~]$
Situation 3: You are doing a import, what would you need to know and consider before starting job.
Challanges:
- How to monitor import jobs, if the dump file is enough big.
- Can you parallelize the import job?
Solution: During import job, its good practice to monitor how much space are available on destination database, which queries should i use to monitor jobs or logs to look for, do i also need addition space except in database.
If there is not enough in tablespace, make sure there is enough space at database level. You can do it by increasing size or adding new datafiles to respective tablespaces. Also one sould not forget to monitor the database alert log.
In addition if your destination database is running in archivelog mode you should regularly monitor the mountpoint where archivelogs are archived.
For importing huge size dumps, generally it is good practice to run the job by creating a shell script and running it on background using unix command nohup.
One can monitor the status of import job by running the following query:
SELECT b.username, a.sid, b.opname, b.target, round(b.SOFAR*100/b.TOTALWORK,0) || '%' as "%DONE", b.TIME_REMAINING,
to_char(b.start_time,'YYYY/MM/DD HH24:MI:SS') start_time
FROM v$session_longops b, v$session a
WHERE a.sid = b.sid ORDER BY 6;
The import/export jobs can be parallelized using the flag PARALLEL and providing appropriate values, but one should consider the no. of CPU on the box. The parallelism also depends on the size of dump file, like specifying PARALLEL=10 for 1GB won’t perform job in 10 degree parallelism. The basic unit storage size for parallelism is 250MB. Checking box’s CPU and memory usage is better during the whole job operation.
Note: The above described situation/tricks are basic guidelines and tricks which will will be helpful in most of the scenarios and if you want more you can visit the offical Oracle doc homepage.