
Oracle Grid Infrastructure stack start initiated but failed to complete at crsconfig_lib.pm line 11809
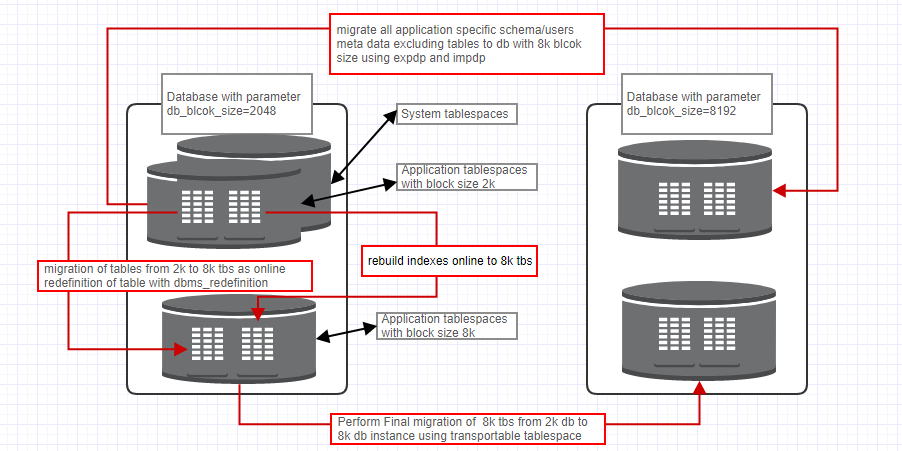
Migration of database with 2k block size to 8k
 Morbi a semper justo, non eleifend elit. Sed nulla nulla, porttitor nec volutpat eu, pulvinar vitae augue. Curabitur tempor quis lorem eget vestibulum. Aenean vel lacinia orci, ac sollicitudin felis. Nunc eros libero, posuere nec massa ac, consectetur sollicitudin elit. Duis tincidunt nunc et neque egestas rhoncus. Curabitur ut euismod lorem, ut rutrum neque. Nullam at sem eros. Nam interdum lectus non cursus viverra.
Morbi a semper justo, non eleifend elit. Sed nulla nulla, porttitor nec volutpat eu, pulvinar vitae augue. Curabitur tempor quis lorem eget vestibulum. Aenean vel lacinia orci, ac sollicitudin felis. Nunc eros libero, posuere nec massa ac, consectetur sollicitudin elit. Duis tincidunt nunc et neque egestas rhoncus. Curabitur ut euismod lorem, ut rutrum neque. Nullam at sem eros. Nam interdum lectus non cursus viverra.
Upgrade Oracle Database from 11g to 12c
Oracle Grid Infrastructure stack start initiated but failed to complete at crsconfig_lib.pm line 11809.
Well, it has been huge troubleshooting. So I think its worth’s of sharing.
First, let’s go to the scene how I encounter this issue.
One of my client’s requirement was to upgrade the Oracle 11gr2 RAC nodes hardware(to new boxes) (2-nodes) with no downtime. So its easy right, at least in Oracle RAC. And I think you guessed it right. It’s simple you can do it in rolling fashion and I planned for the same i.e. first delete any of node, then configure a new node with the same configuration as of node deleted but in the different box with addNode.sh. Well, there were some minor errors and which were fixed easily but a real headache for me was when running root.sh during migration of the last node. I suffered much for troubleshooting the issue and I will share the issue snip:
bash-4.4# /u01/app/11.2.0.4/grid/root.sh
Performing root user operation for Oracle 11g
The following environment variables are set as:
ORACLE_OWNER= grid
ORACLE_HOME= /u01/app/11.2.0.4/grid
Enter the full pathname of the local bin directory: [/usr/local/bin]:
Creating /usr/local/bin directory...
Copying dbhome to /usr/local/bin ...
Copying oraenv to /usr/local/bin ...
Copying coraenv to /usr/local/bin ...
Creating /etc/oratab file...
Entries will be added to the /etc/oratab file as needed by
Database Configuration Assistant when a database is created
Finished running generic part of root script.
Now product-specific root actions will be performed.
Using configuration parameter file: /u01/app/11.2.0.4/grid/crs/install/crsconfig_params
Creating trace directory
Installing Trace File Analyzer
User grid has the required capabilities to run CSSD in realtime mode
OLR initialization - successful
Adding Clusterware entries to /etc/inittab
CRS-4402: The CSS daemon was started in exclusive mode but found an active CSS daemon on node node1, number 2, and is terminating
An active cluster was found during exclusive startup, restarting to join the cluster
Oracle Grid Infrastructure stack start initiated but failed to complete at /u01/app/11.2.0.4/grid/crs/install/crsconfig_lib.pm line 11809.
/u01/app/11.2.0.4/grid/perl/bin/perl -I/u01/app/11.2.0.4/grid/perl/lib -I/u01/app/11.2.0.4/grid/crs/install /u01/app/11.2.0.4/grid/crs/install/rootcrs.pl execution failed
bash-4.4#
So first I checked the 11809 line in the file crsconfig_lib.pm and found nothing interesting:
if ($is_up) {
#Also wait for check cluster to work.
if (!check_service("cluster", 120))
{
die("Oracle Grid Infrastructure stack start initiated but failed to complete");
}
trace ("Oracle CRS stack installed and running");
} else {
error ("Timed out waiting for the CRS stack to start.");
exit 1;
}
return $is_up;
}
I checked the log for root.sh log file in $ORACLE_HOME/cfgtoollogs/crsconfig and found following error:
2018-05-25 15:57:41: Checking the status of cluster
2018-05-25 15:57:46: Executing cmd: /u01/app/11.2.0.4/grid/bin/crsctl check cluster -n node1
2018-05-25 15:57:46: Checking the status of cluster
2018-05-25 15:57:51: Executing cmd: /u01/app/11.2.0.4/grid/bin/crsctl check cluster -n node1
2018-05-25 16:08:00: Checking the status of cluster
2018-05-25 16:08:05: Executing cmd: /u01/app/11.2.0.4/grid/bin/crsctl check cluster -n node1
2018-05-25 16:08:05: Checking the status of cluster
2018-05-25 16:08:10: Executing cmd: /u01/app/11.2.0.4/grid/bin/crsctl check cluster -n node1
2018-05-25 16:08:10: Checking the status of cluster
2018-05-25 16:08:15: ###### Begin DIE Stack Trace ######
2018-05-25 16:08:15: Package File Line Calling
2018-05-25 16:08:15: --------------- -------------------- ---- ----------
2018-05-25 16:08:15: 1: main rootcrs.pl 393 crsconfig_lib::dietrap
2018-05-25 16:08:15: 2: crsconfig_lib crsconfig_lib.pm 11809 main::__ANON__
2018-05-25 16:08:15: 3: crsconfig_lib crsconfig_lib.pm 1369 crsconfig_lib::wait_for_stack_start
2018-05-25 16:08:15: 4: crsconfig_lib crsconfig_lib.pm 1242 crsconfig_lib::start_cluster
2018-05-25 16:08:15: 5: main rootcrs.pl 864 crsconfig_lib::perform_start_cluster
2018-05-25 16:08:15: ####### End DIE Stack Trace #######
2018-05-25 16:08:15: 'ROOTCRS_STACK' checkpoint has failed
2018-05-25 16:08:15: Running as user grid: /u01/app/11.2.0.4/grid/bin/cluutil -ckpt -oraclebase /u01/app/grid -writeckpt -name ROOTCRS_STACK -state FAIL
2018-05-25 16:08:15: s_run_as_user2: Running /bin/su grid -c ' /u01/app/11.2.0.4/grid/bin/cluutil -ckpt -oraclebase /u01/app/grid -writeckpt -name ROOTCRS_STACK -state FAIL '
2018-05-25 16:08:16: Removing file /tmp/zbaCay7eP
2018-05-25 16:08:16: Successfully removed file: /tmp/zbaCay7eP
2018-05-25 16:08:16: /bin/su successfully executed
2018-05-25 16:08:16: Succeeded in writing the checkpoint:'ROOTCRS_STACK' with status:FAIL
2018-05-25 16:08:16: CkptFile: /u01/app/grid/Clusterware/ckptGridHA_cg1.xml
2018-05-25 16:08:16: Sync the checkpoint file '/u01/app/grid/Clusterware/ckptGridHA_cg1.xml'
2018-05-25 16:08:16: Sync '/u01/app/grid/Clusterware/ckptGridHA_cg1.xml' to the physical disk
And looking the log file I found the root.sh hanged running the command /u01/app/11.2.0.4/grid/bin/crsctl check cluster -n node1 as this was repeated many times in logfile.
Searching in google and Oracle knowledge base I found docs which are helpful none of the documents accompany my issue.
Then I went for cluster log file: alertnode1.log
[cssd(18481552)]CRS-1605:CSSD voting file is online: /dev/rhdisk6; details in /u01/app/11.2.0.4/grid/log/node1/cssd/ocssd.log.
2018-05-28 02:40:07.728:
[cssd(18481552)]CRS-1601:CSSD Reconfiguration complete. Active nodes are node1 node2 .
2018-05-28 02:40:10.011:
[ctssd(18874768)]CRS-2403:The Cluster Time Synchronization Service on host node1 is in observer mode.
2018-05-28 02:40:10.298:
[ctssd(18874768)]CRS-2407:The new Cluster Time Synchronization Service reference node is host node2.
2018-05-28 02:40:10.299:
[ctssd(18874768)]CRS-2401:The Cluster Time Synchronization Service started on host node1.
2018-05-28 02:40:22.319:
[ctssd(18874768)]CRS-2409:The clock on host node1 is not synchronous with the mean cluster time. No action has been taken as the Cluster Time Synchronization Service is running in observer mode.
[client(18284818)]CRS-10001:28-May-18 02:40 ACFS-9391: Checking for existing ADVM/ACFS installation.
[client(18284820)]CRS-10001:28-May-18 02:40 ACFS-9392: Validating ADVM/ACFS installation files for operating system.
[client(18284822)]CRS-10001:28-May-18 02:40 ACFS-9393: Verifying ASM Administrator setup.
[client(18284824)]CRS-10001:28-May-18 02:40 ACFS-9308: Loading installed ADVM/ACFS drivers.
[client(18284830)]CRS-10001:28-May-18 02:40 ACFS-9327: Verifying ADVM/ACFS devices.
[client(18284834)]CRS-10001:28-May-18 02:40 ACFS-9156: Detecting control device '/dev/asm/.asm_ctl_spec'.
[client(18284840)]CRS-10001:28-May-18 02:40 ACFS-9156: Detecting control device '/dev/ofsctl'.
[client(18284844)]CRS-10001:28-May-18 02:40 ACFS-9322: completed
2018-05-28 02:40:48.233:
[crsd(24707482)]CRS-1012:The OCR service started on node node1.
2018-05-28 03:10:30.670:
[ctssd(18874768)]CRS-2409:The clock on host node1 is not synchronous with the mean cluster time. No action has been taken as the Cluster Time Synchronization Service is running in observer mode.
Where I found everything is normal the node is able to find the cluster detail and configuration but the cluster servers are not getting up, why?? Probably I don’t have an answer at that time. I begin to look in every log file in $ORACLE_HOME/log/node1 but every error I found in logs and searched in google and oracle MOS all were bootless. I was totally fatigued didn’t know where to move next.
Then I checked the init resources with regard to Oracle RAC:
bash-4.4$ crsctl stat res -t -init
--------------------------------------------------------------------------------
NAME TARGET STATE SERVER STATE_DETAILS
--------------------------------------------------------------------------------
Cluster Resources
--------------------------------------------------------------------------------
ora.asm
1 ONLINE ONLINE node1 Started
ora.cluster_interconnect.haip
1 ONLINE ONLINE node1
ora.crf
1 ONLINE ONLINE node1
ora.crsd
1 ONLINE INTERMEDIATE node1
ora.cssd
1 ONLINE ONLINE node1
ora.cssdmonitor
1 ONLINE ONLINE node1
ora.ctssd
1 ONLINE ONLINE node1 OBSERVER
ora.diskmon
1 OFFLINE OFFLINE
ora.drivers.acfs
1 ONLINE ONLINE node1
ora.evmd
1 ONLINE INTERMEDIATE node1
ora.gipcd
1 ONLINE ONLINE node1
ora.gpnpd
1 ONLINE ONLINE node1
ora.mdnsd
1 ONLINE ONLINE node1
bash-4.4$
Whoo!! I found ora.crsd and ora.evmd were in the intermediate state. I think it would be a good start to look log files for the respective daemon. Hmmm there were some errors but searching against then was again bootless.
I was now struggling much that I begin to crosscheck if any prerequisites I have missed. I even asked some silly questions to the system admin guys and I still have their sneering smile on my mind.
So again I start looking and logs and start to mine them. I looked and looked to all logs ocssd.log, GIPC.log, agent logs and all what ever i found. I looked them so closely that I looked for every string like error, failed, exception, cannot etc with words with negative connotation and searched to google and knowledgebase for solution. But none of them lead me to success. But, I found following in the crsd.log file and found below snip and thought for a while what the message is conveying.
destroy interface 111939a30 { host 'node2', haName '674a-6c55-9728-1e49', local 111933bb0, ip '10.0.10.6:41657', subnet '10.0.10.0', mask '255.255.255.0', mac '', ifname '', numRef 0, numFail 0, idxBoot 0, flags 0x226 }
2018-05-28 02:42:16.264: [GIPCHGEN][2571] gipchaNodeAddInterface: adding interface information for inf 111939a30 { host 'node2', haName '674a-6c55-9728-1e49', local 0, ip '10.0.10.6:41661', subnet '10.0.10.0', mask '255.255.255.0', mac '', ifname '', numRef 0, numFail 0, idxBoot 0, flags 0x2 }
2018-05-28 02:42:17.260: [GIPCHTHR][2314] gipchaWorkerCreateInterface: created remote interface for node 'node2', haName '674a-6c55-9728-1e49', inf 'udp://10.0.10.6:41661'
2018-05-28 02:42:17.260: [GIPCHGEN][2314] gipchaWorkerAttachInterface: Interface attached inf 111939a30 { host 'node2', haName '674a-6c55-9728-1e49', local 111933bb0, ip '10.0.10.6:41661', subnet '10.0.10.0', mask '255.255.255.0', mac '', ifname '', numRef 0, numFail 0, idxBoot 0, flags 0x6 }
2018-05-28 02:42:19.271: [GIPCHGEN][2571] gipchaInterfaceDisable: disabling interface 111939a30 { host 'node2', haName '674a-6c5
From the log file, I conclude that node1 is recognizing node2 but it’s not communicating with node2. Then I start for the solution for node communication failure and intermediate state of resource crsd and evmd. So this was the turning point in my troubleshooting. I found whenever the resource crsd is in the intermediate state, everyone’s first step is to kill the crsd.bin process as they would span automatically. So killing the crsd.bin process in both nodes lead to the end of the troubleshooting the crsd and evmd were online. Thereafter everything went normal and I think its worth’s sharing.